Cnc Milling And Turning,Cnc Milling Turning,Cnc Turning & Milling,Cnc Milling And Cnc Turning Ningbo Leyan Machinery Technology Co., Ltd , https://www.cncleyan.com



How does deep learning help smart behavior analysis and event recognition?
Behavior recognition refers to the technology that identifies and analyzes the behavior of pedestrians by analyzing specific data such as video and depth sensors. This technology is widely used in video classification, human-computer interaction, security monitoring and other fields. Behavior identification includes two research directions: individual behavior identification and group behavior (event) identification. In recent years, the development of the depth imaging technology has made it easy to obtain the depth image sequence of human motion. In combination with a high-precision skeleton estimation algorithm, it can further extract human skeleton motion sequences. Using these motion sequence information, behavior recognition performance has been greatly improved, which is of great significance for intelligent video surveillance, intelligent traffic management, and smart city construction. At the same time, with the increasing demand for pedestrian intelligence analysis and group event awareness, a series of behavior analysis and event recognition algorithms have emerged as a result of deep learning technology. The following will introduce our latest related research.
Figure 1 Definition and application of behavior identification
Human skeleton motion sequence behavior recognition based on hierarchical cyclic neural network
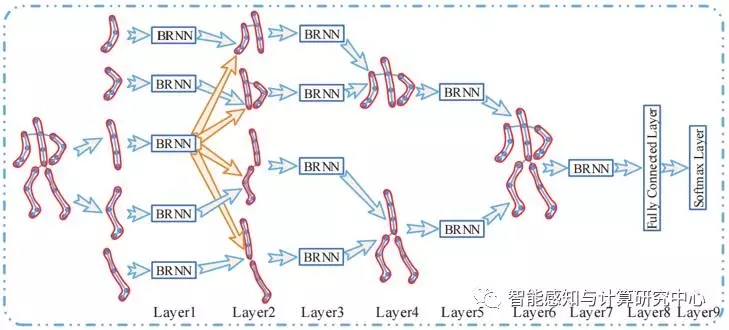
At present, the human skeleton based behavior identification methods can be mainly divided into two categories: 1) Local feature-based methods: This type of method is to extract the features of the human skeleton's local geometric structure at each moment in the sequence, and then use the word packet (bag The model of Words, BoW) is combined with Temporal Pyramid (TP) or Dynamic Time Warping (DTW). This method has no or only partial consideration of the sequence information of the motion sequence. More dependent on local static structure features; 2) Method based on sequence state transition: This method mainly uses HMM to model the dynamic process of behavior evolution. The two main disadvantages are that it not only needs to pre-align sequences, but also It is also necessary to estimate the migration probability of the state transition process. This is a relatively difficult problem and the recognition accuracy is often low. This study is based on the human skeleton motion sequence extracted by Microsoft's Kinect and motion capture system. Combined with the relativity of human motion, this paper proposes a behavior recognition model of human skeleton motion sequence based on recursive neural network. The proposed model first normalizes the nodal coordinates in the extracted human skeleton pose sequence to eliminate the influence of the absolute spatial position of the human body on the recognition process, and uses a simple smoothing filter to smoothly filter the coordinates of the skeleton nodes to enhance the letter The noise ratio finally sends the smoothed data to a hierarchical bidirectional recursive neural network to simultaneously perform deep feature extraction, fusion, and recognition. At the same time, it provides a hierarchical unidirectional recurrent neural network model to meet real-time analysis requirements in practice. . The main advantage of this method is that the end-to-end analysis mode is designed according to the characteristics of the human body structure and the relativity of movement, and the high-precision recognition rate can be realized while avoiding complicated calculations, which is convenient for practical application. This work and its extended versions have been published on CVPR-2015 and IEEE TIP-2016.
Figure 2 Schematic representation of human skeleton sequence behavior recognition based on hierarchical RNN
Behavior Identification Based on Dual-Flow Recurrent Neural Network
Due to the reduction of the cost of depth sensors and the emergence of real-time skeleton estimation algorithms, the research of skeleton-based behavior recognition is becoming more and more popular. The traditional method is mainly based on manual feature design and has limited ability to express movement in behavior. Recently there have been some algorithms based on a recurrent neural network that can directly process raw data and predict behavior. These methods only consider the dynamic evolution of the skeleton coordinates over time, while ignoring their spatial relationship at a certain moment. In this paper, we propose a method based on the dual-flow recurrent neural network shown in Fig. 3, which respectively models the temporal dynamic characteristics and spatial relative relationships of skeleton coordinates. For the time channel, we explored two different structures: a multi-layer recurrent neural network model and a hierarchical cyclic neural network model. For the spatial channel, we propose two effective methods to convert the spatial relationship map of the coordinates into a sequence of joint points to facilitate input into the recurrent neural network. In order to improve the generalization ability of the model, we have explored data enhancement techniques based on three-dimensional coordinate transformations, including rotation, scaling, and shear transformations. The test results in the in-depth video behavior identification standard database show that our method has greatly improved the recognition results of general behaviors, interactive behaviors and gestures. This work has been received by CVPR-2017.
Figure 3 Behavior identification method based on dual stream RNN skeleton
Analysis of Video Events Based on Associated Boltzmann Machines
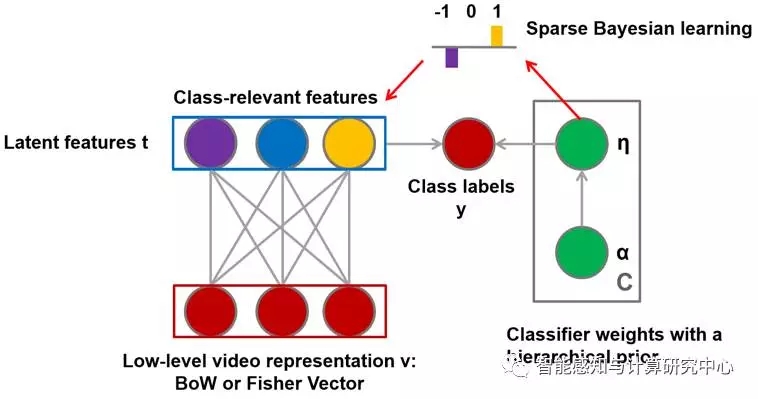
We studied video expression learning in supervised models to expect to use class labels to learn more differentiated expressions that can be used for both video classification and retrieval. We know that due to the semantic gap between low-level visual features and class labels, the computational cost of high-dimensional low-level features for subsequent analysis, and the lack of labeled training samples, unstructured group behaviors are analyzed in uncontrolled online videos. Events are a very challenging task, as shown in Figure 4. To overcome these difficulties, we hope to learn a compact middle-level video expression that contains semantic information. Therefore, we propose a new supervised probability map model: Relevance Restricted Boltzmann Machine (ReRBM), which learns a low-dimensional implicit semantic expression for complex behavior and event analysis. The proposed model has some key extensions based on the restricted Boltzmann machine (RBM): 1) It combines sparse Bayesian learning with RBM to learn discriminative and video-related implicit features; 2) Replace binary random implied units in RBM with non-negative linear units to better interpret complex video content and make variational reasoning applicable to the proposed model; 3) Develop an effective variational EM algorithm for use in Model parameter estimation and reasoning. We evaluated the proposed model on three challenging standard video data sets (Unstructured Social Activity Attribute, Event Video, and Hollywood 2). The experimental results show that compared with some other hidden variable probability map models, as shown in Figure 5, the class-related features learned from the proposed model provide a more discriminative semantic description of the video data, in terms of classification accuracy and retrieval accuracy. The best results were obtained, especially when using few labeled training samples. This work was published at NIPS 2013, the top international conference for machine learning and neural signal processing. The expanded version was published by IJCV 2016, the top international journal in the field of computer vision.
Figure 4 Different types of activities
(simple actions, structured activities, unstructured group events)
Figure 5 Video representation based on a class-restricted Boltzmann machine
Walking behavior-based identification using dual-channel convolutional neural networks
Identification based on walking behavior, that is, gait recognition, generally refers to giving a gait sequence, requiring finding the most similar sequence from a matching library to determine the person's identity in a given sequence. Gait is the only perceptible biological feature in long-distance and uncontrolled situations. The use range can reach as much as 50 meters. It has irreplaceable application prospects and research value in the long-range and wide-range visual monitoring applications. Our proposed method deals with pre-extracted Gait Energy Images (GEI), which are 2D grays that are averaged along the time dimension after aligning the pedestrian silhouettes extracted from the video sequence. Degree image. First, considering the importance of local detail differences in gait recognition based on gait energy maps, local comparisons of multiple points should be better than one global comparison; second, two samples at different perspectives may appear on the surface. The huge difference, if you only consider the comparison of the local areas of the unit, it will be difficult to capture enough information to compare; in addition there is a need to discriminate learning characteristics and comparison models. The above three points can all be implemented in a deep convolutional neural network, so we propose a context-based cross-perspective gait recognition method as shown in Figure 6, in the extremely difficult task of cross-perspective and walking state. Achieve enough acceptable recognition efficiency. Related results have been published on IEEE TMM-2015 and TPAMI-2017.
Figure 6 Gait identification flow chart and proposed model structure diagram
references
[1] Yong Du, Wei Wang, and Liang Wang. Hierarchical Recurrent Neural Network for Skeleton Based Action Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015.
[2] Yong Du, Yun Fu, Liang Wang. Representation Learning of Temporal Dynamics for Skeleton-Based Action Recognition. IEEE Transactions on Image Processing (TIP). 2016.
[3] Hongsong Wang and Liang Wang. Modeling Temporal Dynamics and Spatial Configurations of Actions Using Two-Stream Recurrent Neural Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[4] Fang Zhao, Yongzhen Huang, Liang Wang, Tieniu Tan. Relevance Topic Model for Unstructured Social Group Activity Recognition. Advances in Neural Information Processing Systems (NIPS). 2013.
[5] Fang Zhao, Yongzhen Huang, Liang Wang, Tao Xiang, and Tieniu Tan. Learning Relevance Restricted Boltzmann Machine for Unstructured Group Activity and Event Understanding. International Journal of Computer Vision (IJCV).2016.
[6] Zifeng Wu, Yongzhen Huang, Liang Wang. Learning Representative Deep Features for Image Set Analysis. IEEE Transactions on Multimedia (TMM). 2015.
[7] Zifeng Wu, Yongzhen Huang, Liang Wang, Xiaogang Wang, and Tieniu Tan. A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). 2017.
Note: This article is transferred from IntelliSense and Computation Research Center.
Author: Zhao put, Yong Du, Wanghong Song, Wu Zaifeng.